2023年の夏に、Meta、Openai、Nvidia、Databrksに対する一部の著者が2023年の夏に意図した原因から、人工知能モデルのトレーニングに著作権保護された資料を使用したと非難されています。最近明らかにされたメタの内部メールはそれを示しています会社は著作権保護された本を違法にダウンロードすることを知っていました。
メタの防御は、著作権保護された素材のダウンロードと配布の区別に基づいています。同社は、ダウンロードされた本を配布していないと主張しており、人工知能モデルのトレーニングにそれらを使用することに制限しています。しかし、告発は、メタが彼の仕事の違法性を知っていたと主張しています。
「倫理的な」国境
特に、電子メールはを指しますさまざまな海賊図書館から少なくとも81.7テラバイトのデータをダウンロードする、アンナのアーカイブ、z-library、libgenを含む。 「それは私たちの倫理的閾値を超えているべきです」と文書の1つを読みます。それにもかかわらず、メタはダウンロードを続行し、メソッドを使用してトレースされないようにします。
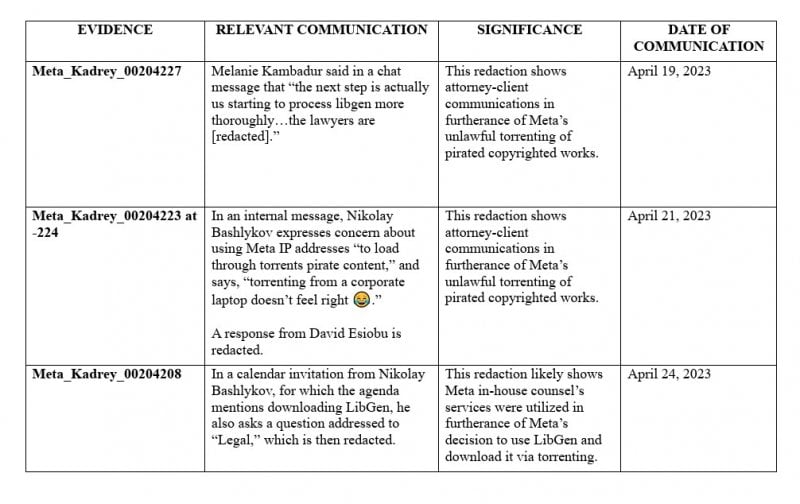
「メタの広大な違法な急流スキームの範囲は驚くべきものです」と著者の文書は、「流量データが大幅に低い著作権侵害の行為-Meta Pirateが著作権保護された作品の量のわずか0.008%のみ」という事実を主張しています。 - 裁判官は、この行為を刑事捜査のために米国検察局に紹介するようになりました。
メタのエンジニアであるNikolay Bashlykovは、海賊版材料の使用について懸念を表明していたでしょう。同じメッセージで、彼は「トレントを介して海賊コンテンツをロードするためのメタIPアドレスの使用に関する懸念」を表明しました。
2023年9月、バシュリコフは絵文字を放棄し、法務チームに直接相談し、「トレントの使用はファイルの「共有」、または外部のコンテンツの共有を意味することを意味するという電子メールで下線を引いています。法的に正しい」。
審査員が会社の仕事をどのように評価するかを確認します。どう思いますか?以下のコメントで教えてください。その間。